
ChatGPT is no longer the default winner by momentum alone. Its traffic share fell from 86.7% to 64.5% in the 12 months leading into 2026, a 22.2 percentage point drop as users shifted toward Claude and Gemini for more specialized strengths, according to Artificial Corner’s market analysis.
That number changes how I look at chatgpt vs claude vs gemini. This isn’t a popularity contest anymore. It’s a workflow decision. For a freelancer, that might mean choosing the model that follows instructions best. For a small business, it might mean avoiding a model that looks cheap at the subscription layer but turns expensive once API usage, staff time, and rework enter the picture. For a security team, one bad hallucination can outweigh every flashy feature.
The bigger story is fragmentation. One model now wins on research depth, another on current information and cost efficiency, and another on breadth and integrations. If you still choose AI the way people did a year ago, you’re probably choosing based on stale assumptions, not present reality. That’s why even broader concern pieces such as this warning-focused Tech Verdict report on ChatGPT matter in a comparison like this. AI selection now sits at the intersection of productivity, cost control, and risk management.
Table of Contents
- The Great AI Shakeup of 2026
- Meet the Three Titans of AI
- Head-to-Head Performance Deep Dive
- Analyzing the True Cost of Each AI
- Comparing Privacy Security and Reliability
- The Best AI Model for Your Specific Job
- The Final Verdict A Recommendation Framework
- Frequently Asked Questions
The Great AI Shakeup of 2026
The old framing was simple. ChatGPT led, everyone else chased, and most buyers could stop there.
That framing broke when users started optimizing for specific jobs instead of general familiarity. The most important shift in 2026 isn’t just that ChatGPT lost share. It’s that buyers now expect different models to win different tasks.
Why the market split
Three forces pushed the market apart.
- Specialized strengths became visible: Claude built a reputation for precise instruction-following and long-context work. Gemini gained attention for real-time web access and lower API costs. ChatGPT stayed strong where breadth and integrations mattered.
- Blind testing reduced brand bias: Once model labels disappeared, people judged outputs more harshly on actual usefulness.
- Cost moved from consumer pricing to operational pricing: A flat monthly plan looks simple, but businesses don’t run on simple prompts. They run on repeated tasks, integrations, revisions, and team adoption.
What that means in practice is straightforward. The “best” AI now depends less on the homepage demo and more on your failure mode. Do you suffer from weak current information, bloated output, prompt drift, expensive automation, or factual errors in sensitive work?
The winning model isn’t the one that impresses you in five minutes. It’s the one that creates the least friction in month three.
What this means for buyers
If you’re comparing chatgpt vs claude vs gemini today, you’re not really choosing one chatbot. You’re choosing between three product philosophies.
Claude is increasingly the analyst’s model. Gemini is the operator’s cost-aware utility model. ChatGPT is the generalist with the broadest consumer familiarity and strong structured output habits.
That split is healthy. It also makes lazy buying more expensive.
Meet the Three Titans of AI
Before judging outputs, it helps to understand what each system is trying to be.

ChatGPT and GPT-5.4
ChatGPT’s core advantage is reach. OpenAI has spent years turning its model into a default layer inside broader tools and workflows. That matters because many teams don’t buy the “best model” in the abstract. They buy the one their staff can deploy quickly.
GPT-5.4 looks strongest when you need a broad, flexible assistant that can handle many task types without forcing a specialized setup. In the verified data, it’s described as balancing breadth across tasks and excelling in high-volume structured output generation rather than deep contextual analysis.
That’s an important distinction. ChatGPT often feels efficient because it can move fast across formats. But speed and breadth don’t automatically equal depth.
Claude and Claude Opus 4.6
Anthropic’s flagship feels designed for people who care about precision over spectacle. Claude Opus 4.6 stands out in the verified data for long-context coherence, deep research, and instruction-following accuracy across complex prompts.
Its personality as a product is narrower and more deliberate. If you give Claude a messy brief, lots of reference material, and strict formatting rules, it usually behaves like it understands that the assignment is to stay aligned, not to improvise.
That makes it especially attractive to developers, researchers, legal-adjacent users, and teams working with policy-heavy documentation. The leadership divide between OpenAI and Anthropic also reflects this broader product split, a tension visible in industry coverage such as this Tech Verdict piece on Sam Altman and Dario Amodei.
Gemini and Gemini 3.1 Pro
Google’s pitch is different. Gemini 3.1 Pro is the model for users who value current information, ecosystem fit, and price efficiency.
The verified data positions Gemini as an all-around performer that never bombed in blind tests. That phrase matters more than it first appears to. Gemini may not dominate every category, but it often avoids the worst kind of AI failure, which is being confidently unusable.
There’s another angle. Gemini 3.1 Pro led on MMLU at 94.1% in benchmark testing cited by Artificial Corner. Benchmarks never tell the whole story, but they do support the idea that Gemini’s strengths lean toward reasoning and broad knowledge evaluation, especially when paired with Google’s live data advantages.
The practical identity of each model
Here’s the simplest way I’d describe them after heavy use:
| Model | Best identity | Best fit |
|---|---|---|
| ChatGPT GPT-5.4 | Broad generalist | Teams that want versatility and structured output |
| Claude Opus 4.6 | Precision analyst | Research, coding, long prompts, instruction-heavy tasks |
| Gemini 3.1 Pro | Cost-aware live-data assistant | Search-driven workflows, Google-centric teams, high-volume API use |
If you start from those identities, the later benchmark results make more sense.
Head-to-Head Performance Deep Dive
A small business choosing the wrong model does not just lose time. It can add review work, re-prompting, and API waste to every repeated task. That is why raw quality matters here. Better output lowers total cost of ownership long before the pricing table enters the discussion.
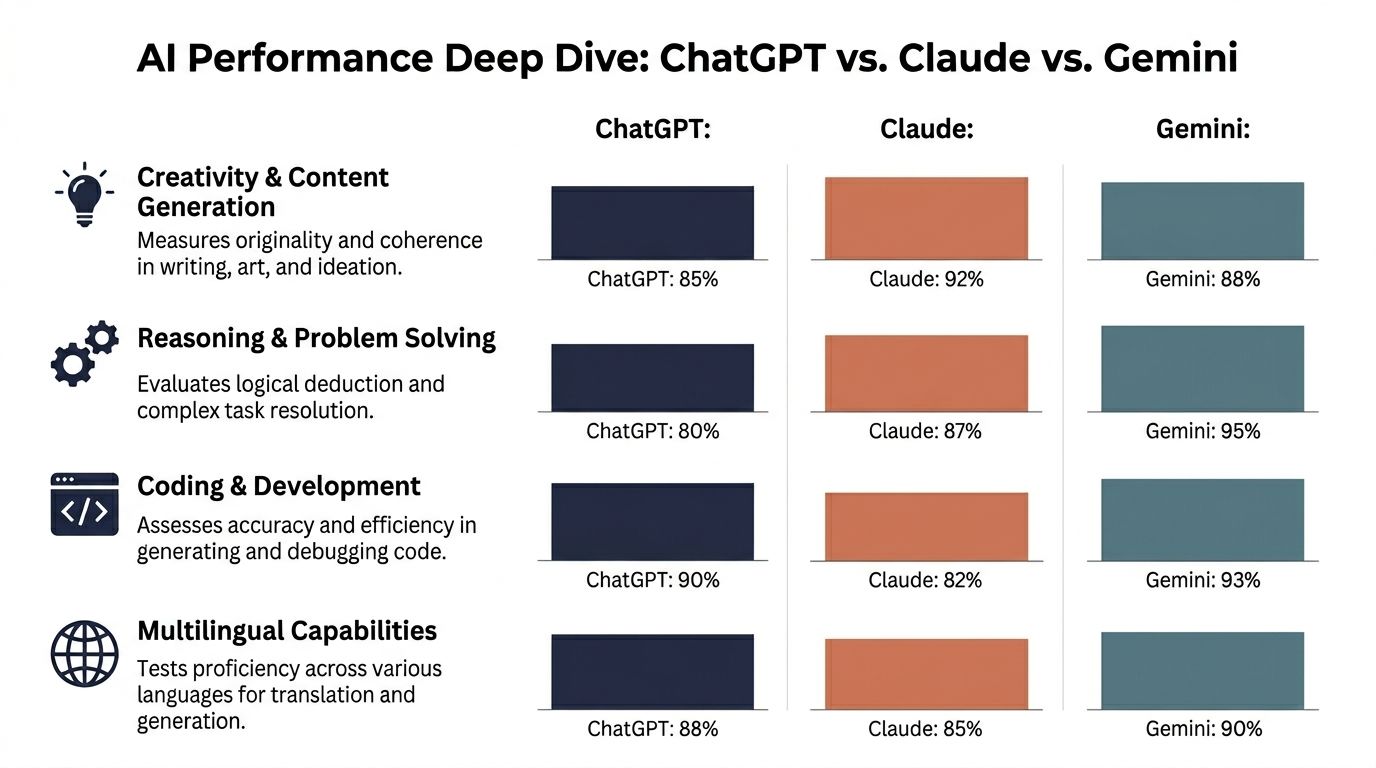
The cleanest signal comes from blind evaluation. In an independent 2026 test with eight rounds, Claude Opus 4.6 won four rounds, Gemini won three, and ChatGPT won one, based on the comparison from A.I. Blew My Mind. The more revealing detail is margin. Claude’s wins ranged from 35 to 54 points. Gemini’s wins were tighter, at 3 to 11 points. ChatGPT’s single win was narrower in scope than its market share would suggest.
That pattern matches real buying risk.
Claude looks best when the task has a high penalty for being subtly wrong. Gemini looks best when teams need steady performance across mixed workloads and cannot afford frequent failure modes. ChatGPT still performs well in broad business use, but its advantage is less about dominance and more about familiarity, workflow speed, and packaging.
Performance under real business pressure
Benchmarks matter less than failure costs. A marketing consultant, paralegal, or operations lead is not grading style alone. They are paying for usable output that survives review.
Claude stands out in long, instruction-heavy sessions. It keeps constraints in memory, follows format rules with fewer retries, and holds up better when a prompt includes source material, edge cases, and output requirements all at once. For teams building client deliverables or internal documentation, that usually means fewer prompt revisions and less human cleanup.
That is a direct cost advantage, even before pricing.
Gemini’s strength is different. It combines broad reasoning performance with current-information utility, which makes it attractive for workflows tied to changing facts. For buyers evaluating Google’s model in more detail, Tech Verdict’s analysis of Gemini 3.1 Pro’s reasoning capabilities is useful context. In practice, Gemini earns its place when the job includes market monitoring, competitive checks, search-grounded drafting, or any workflow already living inside Google Workspace.
ChatGPT remains strong in structured generalist work. It is often the fastest route to a usable first draft, a framework, or a standardized business output. That matters for sales teams, operators, and managers who need decent output quickly and do not want to spend extra time tuning prompts.
Where each model wins, and what that means for TCO
Research and long-form synthesis
Claude is the strongest option for research synthesis that has to be read by another professional. Earlier reporting cited in this article found that Claude tends to produce tighter reports, while competing models often return much longer drafts for the same task. In business settings, shorter and denser usually wins. Executives read it. Analysts can verify it faster. Agencies spend fewer billable hours trimming AI-generated excess.
A 30-page answer can look impressive and still cost more than it saves.
Live information and changing contexts
Gemini is the better choice for work that expires quickly. If your staff tracks pricing changes, product launches, policy shifts, or market sentiment, current information matters more than polished phrasing. Gemini’s practical edge is not just “good at search.” It fits workflows where stale output creates rework, and rework is one of the hidden costs that buyers underestimate.
For a small business with lightweight automation needs, that can outweigh a small quality gap on writing style.
Coding and technical implementation
Claude is still the model I would give to a lean engineering team that needs one assistant for serious implementation work. It is more reliable with long context, better at staying inside spec, and less likely to drift after several turns. That reduces debugging time, which is often more expensive than token spend.
For technical teams, “production-ready” should be interpreted carefully. No model is fully production-ready without review. Claude gets closer on the first pass, which lowers labor cost.
Structured business output
ChatGPT still has a clear role. It works well for repeatable outputs such as meeting summaries, planning frameworks, draft emails, proposal outlines, and standard operating procedure templates. If a team values speed, a familiar interface, and broad competence over top-tier depth, ChatGPT often provides the best throughput per employee.
That does not make it the best model overall. It makes it the easiest one to deploy quickly across non-technical functions.
A practical ranking by workflow
| Workflow | Winner | Why it wins in practice |
|---|---|---|
| Client research, analyst briefs, document-heavy reasoning | Claude | Best at maintaining context, following detailed instructions, and producing outputs that need less editing |
| Search-grounded drafting, market monitoring, Google-centric operations | Gemini | Strong fit for current-information tasks and lower-friction use inside Google workflows |
| High-volume business writing and standardized internal tasks | ChatGPT | Fast, familiar, and effective for repeatable structured outputs |
| Coding across long sessions and multi-file problem solving | Claude | Fewer context drops and better adherence to technical constraints |
| Mixed workloads where failure avoidance matters | Gemini | More even performance across categories, with fewer dramatic misses |
The practical verdict is straightforward. Claude wins on output quality where mistakes are expensive. Gemini wins on consistency in live-information workflows and often makes more sense operationally for cost-sensitive teams. ChatGPT wins on deployment speed for broad business use.
For small businesses and professional teams, that distinction matters more than headline benchmark bragging rights. The best model is the one that produces acceptable work with the fewest retries, the least manual correction, and the lowest risk of an expensive hallucination.
Analyzing the True Cost of Each AI
A $20 monthly seat can turn into a four-figure workflow once you count API calls, setup hours, and staff time spent checking bad answers.
That gap is where many small business AI decisions go wrong. The subscription fee is visible. The expensive part often sits in labor, middleware, and exception handling.
Subscription price hides the real bill
On the surface, ChatGPT, Claude, and Gemini all sit in a similar range for paid individual access. That makes them look interchangeable in procurement discussions. They are not interchangeable once a team moves from occasional prompting to embedded use in CRM updates, intake forms, document review, or client-facing drafting.
The clearest pricing gap in the source set appears at the API layer. Earlier reporting cited Gemini 2.5 Flash at $0.30 per million input tokens and Claude Opus 4.6 at $5 per million input tokens. For firms processing large volumes of support tickets, transcripts, or internal documents, that difference changes the economics quickly.
| Model | Pro Subscription | API Input Cost ($/1M tokens) | API Output Cost ($/1M tokens) |
|---|---|---|---|
| ChatGPT | ~ $20/month per user | Not verified in provided data | Not verified in provided data |
| Claude Opus 4.6 | ~ $20/month per user | $5 | Not verified in provided data |
| Gemini 2.5 Flash / Gemini family | ~ $20/month per user | $0.30 | Not verified in provided data |
Incomplete pricing data is a cost signal too. If a buyer cannot model likely usage with confidence, budgeting gets harder, especially for firms without an engineer or finance lead monitoring token spend week by week.
The hidden cost is rework
After testing these models across client research, drafting, spreadsheet extraction, and internal knowledge tasks, I would frame total cost of ownership in three buckets.
First, usage cost. Token pricing matters most in repetitive, machine-scaled workflows such as tagging leads, summarizing calls, or classifying inbound requests.
Second, integration cost. A cheaper model can still be the more expensive choice if it needs custom routing, prompt scaffolding, or more QA logic before staff can rely on it. In one referenced video analysis, the same source tied ChatGPT’s broad pre-built integration support and documented development-time savings to lower implementation friction for teams using tools like Zapier. That matters for small firms without an internal developer, especially if they need a working system in days rather than weeks: https://www.youtube.com/watch?v=uT8ha6oIm2E
Third, error cost. This is the one buyers underestimate. If a model produces a polished but wrong answer in a legal, financial, compliance, or client-delivery workflow, the cost is not the token bill. The cost is staff review time, reputational risk, and sometimes a downstream correction that takes longer than doing the task manually.
The cheapest AI is the one that creates the fewest expensive interruptions.
Which model actually costs less in practice
Gemini usually has the lowest TCO for high-volume, lower-stakes automation.
If your workload is classification, routing, short summaries, or search-connected tasks inside Google-heavy operations, low token costs can outweigh quality differences. This is the strongest fit for agencies, ecommerce teams, and operations managers running many small actions every day.
ChatGPT often has the lowest TCO when deployment speed matters more than model efficiency.
A solo consultant or 15-person business can spend more on setup than on AI usage. In that case, broad integration support, familiar UX, and easier handoff across non-technical staff can beat a theoretically cheaper API. Paying a bit more per task is often rational if it saves a week of implementation time.
Claude often has the lowest TCO in high-consequence professional work.
Claude’s higher usage cost can still be the better deal when the output goes into board briefs, policy drafts, technical documentation, contract review, or research synthesis. In those workflows, one avoided hallucination or one fewer rewrite cycle can cover a large pricing gap. Teams in regulated or sensitive environments should also factor in governance overhead and review processes tied to efforts to strengthen cybersecurity AI risk controls, because those processes raise the cost of every model failure.
My TCO verdict
For a small business buying AI with its own time and cash, the winner depends on what creates the biggest expense inside the workflow.
- Choose Gemini if you run lots of low-risk automations and care most about usage efficiency.
- Choose ChatGPT if you need the fastest path from idea to working workflow across common business tools.
- Choose Claude if your staff spend expensive hours fixing errors, verifying claims, or rewriting weak drafts.
The practical question is not which model is smartest in isolation. It is which one produces usable work at the lowest combined cost of software, implementation, supervision, and risk.
Comparing Privacy Security and Reliability
A single bad answer can wipe out a year of software savings. That is the core privacy and reliability question for small businesses using AI in legal review, compliance, client research, procurement, or internal policy work.
Monthly subscription price is easy to compare. Error handling is not. If a model produces a confident false claim, your team pays for verification time, revision cycles, delayed approvals, and in some cases outside counsel or client cleanup. For professional buyers, reliability is part of total cost of ownership.
Reliability is a cost control mechanism
After testing these models across long documents, source-based summaries, and policy-style prompts, I would group them this way for professional use:
- Claude is the safest default for high-consequence writing and analysis.
- ChatGPT is reliable enough for many internal workflows, but it benefits from tighter reviewer oversight.
- Gemini is useful when current information matters, yet it usually needs more validation in factual or sensitive work.
That ranking matters because reliability gaps do not stay contained inside the model output. They spill into operations. A compliance manager who has to re-check every citation has a different cost structure from a sales team drafting low-risk outreach. The model with the lowest sticker price can become the most expensive option once review time is added.
Claude stands out because it tends to invent less when the prompt is ambiguous or evidence is thin. That trait is easy to undervalue in benchmarks and easy to notice in production. In contract summaries, policy comparisons, and executive briefs, a restrained model often creates more usable work than a more fluent one. Fewer unsupported assertions means fewer expensive interruptions.
Privacy choices affect workflow design
Privacy is not only a policy page question. It changes where AI can sit inside a business process.
If your team handles client records, legal drafts, security documents, or regulated internal material, the practical issue is whether staff can use the model without creating a second approval layer. A tool that triggers constant escalation to IT, legal, or compliance slows adoption and raises operating cost. That is why governance work such as efforts to strengthen cybersecurity AI risk controls matters to buyers. It affects vendor review, internal sign-off, and how much human monitoring each workflow requires.
I am avoiding hard rankings on retention policies or enterprise data handling here because those details change often and were not fully verified in the source set used for this article. The safer comparison is operational.
| Workflow concern | Best fit | Why |
|---|---|---|
| Board materials, policy drafts, contract summaries | Claude | Lower tendency to drift or overstate weak evidence |
| Time-sensitive research with live information needs | Gemini | Better fit when fresh retrieval is part of the task |
| Broad team adoption across mixed business tasks | ChatGPT | Strong general utility and easier fit for many common workflows |
My reliability verdict
For small businesses and professionals, Claude wins this category.
Not because it is perfect. Because the cost of being wrong is usually higher than the cost of being slower or slightly more expensive. ChatGPT finishes second because it works well across many business contexts and can be dependable with a disciplined review process. Gemini is the better choice only when access to current information outweighs the extra checking burden.
If your outputs reach clients, executives, regulators, or auditors, the best model is the one that creates the fewest cleanup tasks after the first draft.
The Best AI Model for Your Specific Job
A wrong model choice rarely shows up first in the subscription fee. It shows up later, in rework, verification time, failed automations, and staff hours spent forcing a tool into workflows it does not fit.

For a freelancer, that hidden cost may be an extra 20 minutes polishing each draft. For a small firm, it may be a month of API overages, brittle integrations, or one confident hallucination in a client-facing document. The best model for a job is the one that lowers total operating cost for that specific workflow.
Best picks by persona
The developer
Winner: Claude Opus 4.6
As noted earlier, Claude handles long context and complex instructions better once a coding task stops being a clean benchmark and starts looking like real work. That matters in production settings where prompts include documentation, legacy code, edge cases, and architecture constraints in the same thread.
Why Claude usually costs less over time for developers:
- fewer retries on long, messy prompts
- better continuity across multi-step debugging and refactoring
- less prompt scaffolding needed to keep the model on task
Runner-up: ChatGPT
ChatGPT fits teams that need an all-purpose assistant inside a broader software stack. If engineering work is mixed with drafting, project coordination, and light analysis, its integration convenience can outweigh Claude’s quality edge.
The content marketer
Winner: Claude
Content teams do not just buy words. They buy edit efficiency. Claude is the stronger choice when brand voice needs to stay tight, claims need to stay controlled, and briefs include many constraints. In those conditions, cleaner first drafts often matter more than raw speed.
Runner-up: Gemini
Gemini works well for content operations tied closely to Google workflows or topics that change quickly. It is the better value if the bottleneck is gathering current information rather than refining messaging.
The academic researcher or analyst
Winner: Claude
Analysts, consultants, and researchers pay for precision. They also pay for every hour spent checking citations, untangling fuzzy reasoning, or trimming bloated output. Claude is the better fit for source-heavy prompts and nuanced synthesis because it tends to produce material that is easier to audit and pressure-test.
Runner-up: Gemini
Choose Gemini if the assignment depends heavily on recent developments and fast retrieval. For market scans, news-sensitive analysis, and early-stage research, recency can outweigh deeper synthesis.
The small business owner
Winner: Gemini
Small businesses usually feel AI costs in three places. Monthly seats, usage-based billing, and setup time. Gemini wins when the goal is affordable automation across customer support drafts, internal summaries, and basic workflow triggers, especially for firms already using Google Workspace.
It also reduces one common small-business problem. Owners often overpay for a premium model when the actual need is not top-tier reasoning, but predictable operating cost across many low-risk tasks.
Runner-up: ChatGPT
ChatGPT is the better purchase for teams that want fast adoption with minimal configuration. Its ecosystem and familiar workflow design can reduce training time, which is a real cost for lean teams without technical staff. If you are comparing broader software choices around these models, this guide to best AI tools for business adds useful context.
The everyday user
Winner: ChatGPT
ChatGPT remains the easiest default for people who switch constantly between everyday tasks such as writing, planning, summarizing, and general Q&A. For this group, convenience is the product. A small quality difference on specialized tasks matters less than a tool that feels fast, familiar, and easy to use every day.
Runner-up: Gemini
Gemini is a good alternative for users who want stronger ties to Google services and more live-information utility.
When a two-model stack beats a single winner
One model is often enough for individuals. It is often the wrong setup for a business.
A two-model stack makes financial sense when high-volume work and high-risk work are different categories inside the same company. Use the cheaper model for triage, extraction, and routine drafting. Use the more reliable model for final outputs that reach clients, regulators, executives, or legal reviewers.
The pairings I recommend most often are:
- Claude + Gemini for firms that need strong reasoning on high-stakes tasks and lower-cost automation at scale
- ChatGPT + Claude for teams that want easier adoption plus better performance on writing, analysis, and coding
- ChatGPT + Gemini for organizations centered on accessibility, live retrieval, and broad staff usage
The strongest pattern is simple. Draft with one model. Verify with another. That setup raises direct spend, but it can lower total cost if it prevents bad outputs from reaching expensive parts of the business.
The Final Verdict A Recommendation Framework
Here’s the cleanest recommendation I can give after weighing performance, cost, and reliability.
If your primary need is deep research, long prompts, coding quality, or factual dependability, choose Claude Opus 4.6. It won the strongest quality signals, its blind-test victories were decisive, and its reliability profile is the best fit for serious professional work.
If your primary need is cost-efficient scale, live information, or Google-centric workflows, choose Gemini. It’s the best choice when current context and API economics matter more than absolute depth.
If your primary need is a broad general-purpose assistant with familiar workflows and strong structured output, choose ChatGPT. It’s no longer the undisputed leader, but it remains useful where versatility and integration convenience outweigh narrower benchmark losses.
Here’s the shortest possible framework:
- Choose Claude if mistakes are expensive.
- Choose Gemini if volume is expensive.
- Choose ChatGPT if setup time is expensive.
That’s the answer to chatgpt vs claude vs gemini in 2026. There isn’t one universal champion. There are three different winners, depending on what kind of cost you’re trying to avoid.
Frequently Asked Questions
Can I move my prompts from one model to another
Yes, but don’t expect identical behavior. Claude tends to reward detailed instructions and examples. ChatGPT usually adapts well to broad prompts. Gemini often performs best when the task benefits from current information or Google ecosystem context. Move the prompt, then tune formatting, constraints, and expected output style.
Which model is easiest for non-technical teams
ChatGPT is usually the easiest starting point for general business users because its broad assistant identity is familiar. Gemini is also approachable for teams already living inside Google tools. Claude often gives the best output in demanding tasks, but users get more from it when they write tighter prompts.
Which model is best for non-English work
The verified source set doesn’t provide comparative non-English benchmark data, so I wouldn’t declare a hard winner. In practice, test your top three workflows directly in the language you care about. Translation, tone control, and terminology fidelity can vary a lot by task type.
Should I use one model or multiple models
Use one model if simplicity matters more than optimization. Use multiple models if your work spans different risk levels. A common pattern is to draft with one model and verify or refine with another.
How should a small business run an evaluation
Use a short pilot. Pick real tasks, not demo prompts. Test one research task, one customer-facing writing task, one structured internal task, and one high-risk factual task. Then compare output quality, staff correction time, and billing behavior. That will tell you more than any marketing page.
Tech Verdict covers AI platforms, cybersecurity tools, and practical buying guides for people who need clear answers before they spend money. If you’re comparing assistants, automations, or privacy tools, visit Tech Verdict for more hands-on analysis and side-by-side recommendations. Which model are you using most right now, and has your choice changed over the past year?







{kind=link}